While the VAE is a generative model that is capable of producing new samples from a learned data distribution, its main objective is to learn the latent space representation and the corresponding distribution. Generative adversarial networks (GANs) are explicitly set up to optimize for the generative tasks [9]. In their essence, GANs were proposed as generative models that learn a mapping from a random noise vector \(z\) to an output \(y\), \(G: z \to y\)[9] . The architecture of a GAN is composed of two main components: the generator and the discriminator. The generator \(G\) is trained to produce samples based on an input noise vector \(z\) that cannot be distinguished from “real” images by an adversarially trained discriminator, D, which is trained to do as well as possible at detecting the generator “fakes” [9].
The conventional generator in a GAN is basically an encoder-decoder scheme similar to that in an AE where the input is passed through a series of layers that progressively downsample it (i.e., encoding), until a bottleneck layer, at which point the process is reversed (i.e., decoding) [9, 10, 28]. On the other hand, the discriminator is a convolutional neural network whose objective is to classify “fake” and “real” images. Hence, its structure differs from that of the generator and resembles a typical two-class classification network [9, 10, 28]. This adversarial scheme is represented in the objective function given as:
\[\underset{G}{\mathrm{min}}\underset{D}{\mathrm{max}}{\mathbb{E}}_{x}\left[logD\left(x\right)\right]+{\mathbb{E}}_{z}\left(log\left[1-D\left(G\left(z\right)\right)\right]\right)\qquad \qquad \qquad \quad \text{(4)}\]
where \(D\left(•\right)\) represents the probability of a sample being real; i.e., not generated by \(G\). After training, the generator part of the GAN is used to generate new samples using random noise vectors while the discriminator is discarded as it is only needed for the training process [9, 10, 28].
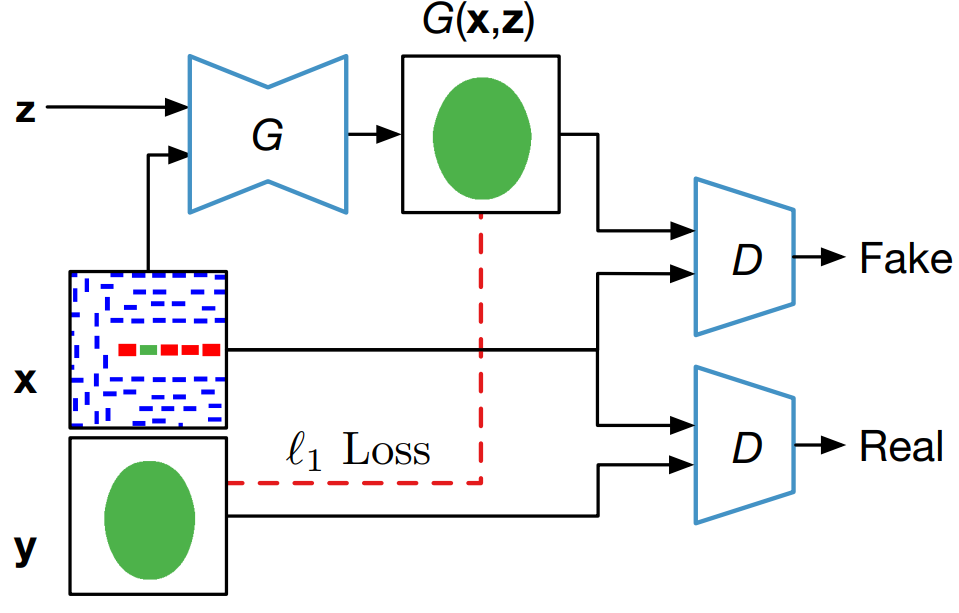
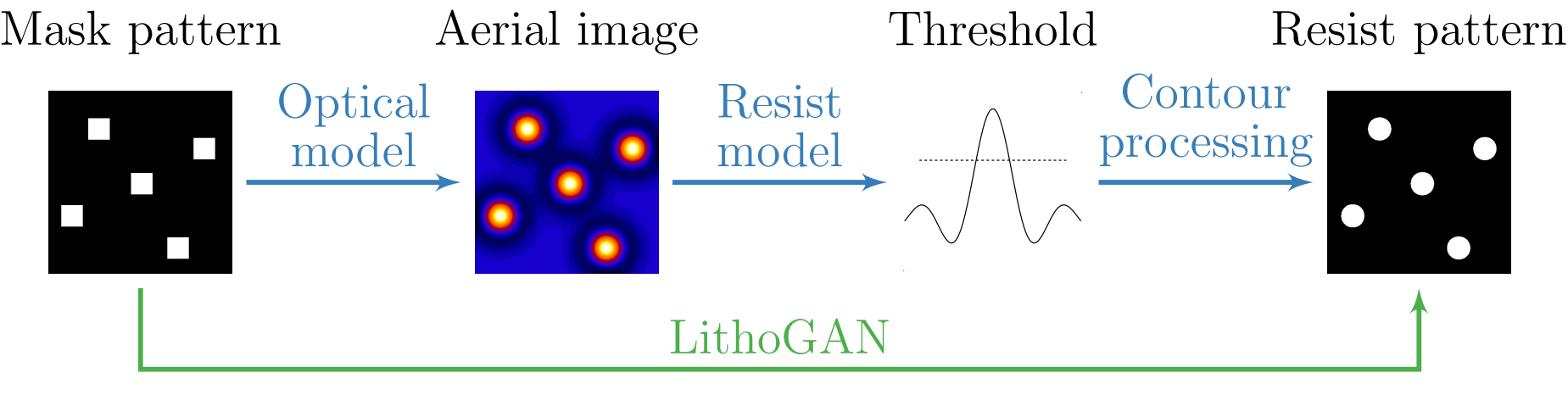
The introduction of GANs has paved the way for a new class of models that stemmed from the original GAN concept. In fact, different versions of GANs, tailored towards specific domain and applications, were proposed especially for image related tasks. Among these are the CGANs which, in contrast with original GANs, learn a mapping from an observed image \(x\) and random noise vector \(z\), to \(y\), \(G : \left\{ x, z\right\} \to y\). Technically, CGANs have changed the objective from a pure generative one to a domain-transfer task capable of establishing a mapping between images in different domains. Its applications span different domains ranging from image coloring to aerial to map, edge to photo translations, and medical applications among others [29]. Looking at it abstractly, such models can be viewed in many fields as data-trained simulators or optimizers that can perform complex operations such as lithography simulation as shown in [15]. In fact, the CGAN model is the most adopted generative model for EDA applications [15, 16, 18, 19, 21, 22].
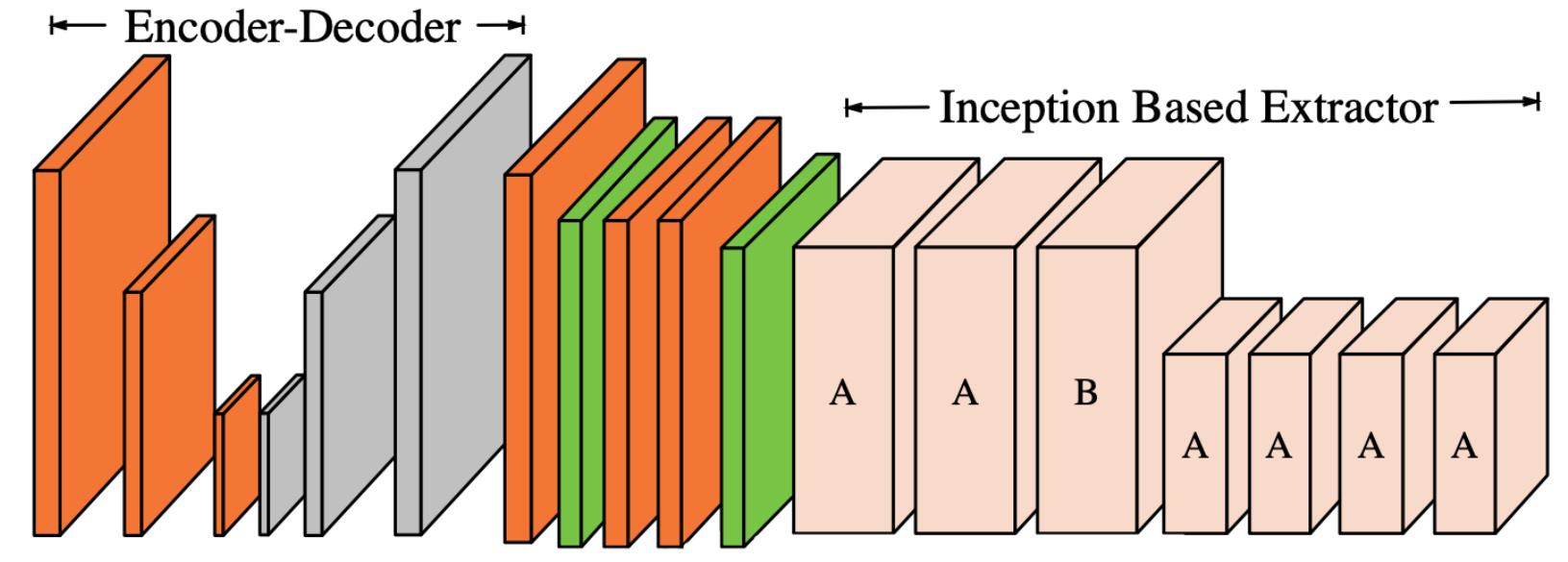
Figure 2.
CGAN for lithography modeling [15]. The architecture of the CGAN used for end-to-end lithography simulation is shown in Fig. 2 where \(G\) translate an image from the layout domain to the resist shape domain, and \(D\) examines image pairs to detect fake ones (further details about this application are presented in Section 3.3). Mathematically, one form of a loss function used for training the CGAN can be given as [10, 29]:
\[{\mathcal{L}}_{CGAN}\left(G,D\right)={\mathbb{E}}_{x,y}\left[logD\left(x,y\right)\right]+{\mathbb{E}}_{x,z}\left(log\left[1-D\left(x,G\left(x,z\right)\right)\right]\right)+\lambda {\mathbb{E}}_{x,z,y}l\left(y,G\left(x,z\right)\right)\qquad \qquad \qquad \text{(5)}\]
where \(x\) is a sample in the input domain and \(y\) is its corresponding sample in the output domain. Comparing equations (4) and (5), one can notice the addition of the loss term which penalizes the difference between the generated sample G(\(x\), \(z\)) and its corresponding golden reference \(y\). Different loss functions are adopted in different CGAN models including l1 -norm and l2 -norm